We tackle the problem of 3D point cloud localization based on a few natural linguistic descriptions and introduce a novel neural network, Text2Loc, that fully interprets the semantic relationship between points and text. Text2Loc follows a coarse-to-fine localization pipeline: text-submap global place recognition, followed by fine localization. In global place recognition, relational dynamics among each textual hint are captured in a hierarchical transformer with max-pooling (HTM), whereas a balance between positive and negative pairs is maintained using text-submap contrastive learning. Moreover, we propose a novel matching-free fine localization method to further refine the location predictions, which completely removes the need for complicated text-instance matching and is lighter, faster, and more accurate than previous methods. Extensive experiments show that Text2Loc improves the localization accuracy by up to 2 times over the state-of-the-art on the KITTI360Pose dataset. We will make the code publicly available.
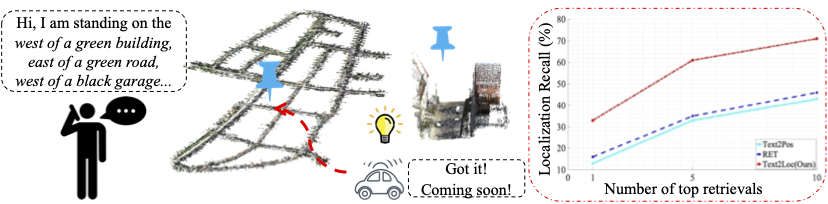
Text2Loc architecture: It consists of two tandem modules: Global place recognition and Fine localization. \textit{Global place recognition.} Given a text-based position description, we first identify a set of coarse candidate locations, that is, "submaps," which potentially contain the target position and serve as the coarse localization of the query. This is achieved by retrieving the top-k nearest cells from a previously constructed database of submaps using our novel text-to-cell retrieval model. \textit{Fine localization.} We then refine the center coordinates of the retrieved submaps via our designed matching-free position estimation module, which adjusts the pose to increase accuracy.

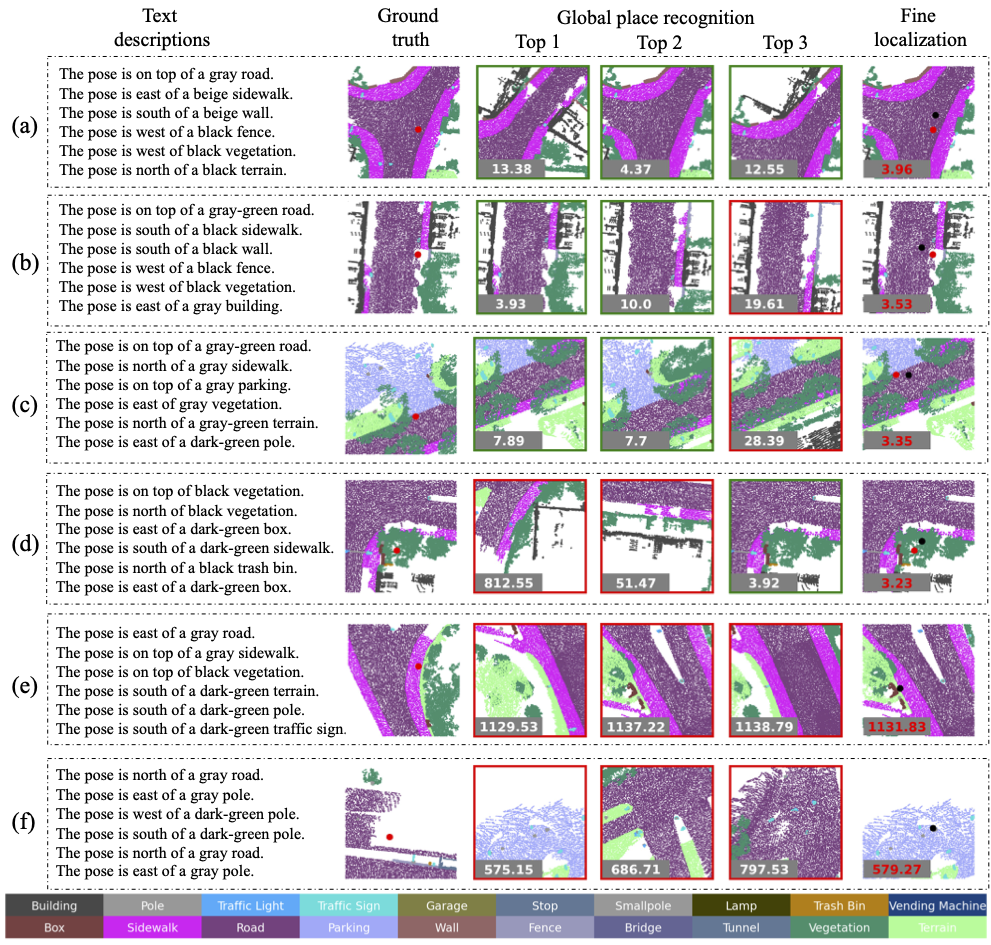
Qualitative localization results on the KITTI360Pose dataset. In global place recognition, the numbers in top3 retrieval submaps represent center distances between retrieved submaps and the ground truth. Green boxes indicate positive submaps containing the target location, while red boxes signify negative submaps. For fine localization, red and black dots represent the ground truth and predicted target locations, with the red number indicating the distance between them.
@InProceedings{xia2024text2loc,
title={Text2Loc: 3D Point Cloud Localization from Natural Language},
author={Xia, Yan and Shi, Letian and Ding, Zifeng and Henriques, Jo{\~a}o F and Cremers, Daniel},
journal={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2024}
}
}